#
Resumir
#
¿Qué es?
Esta extensión te permite crear, almacenar y utilizar resúmenes generados automáticamente basados en los eventos que suceden en tus chats. La resumición puede ayudar a esbozar los detalles generales de lo que está sucediendo en la historia, que podría interpretarse como una memoria a largo plazo, pero toma esa declaración con una pizca de sal. Dado que los resúmenes se generan mediante modelos de lenguaje, los resultados pueden perder algunos detalles importantes o contener alucinaciones, por lo que siempre se aconseja realizar un seguimiento del estado del resumen y corregirlo manualmente si es necesario.
#
Configuración común
La extensión de resumición está instalada en SillyTavern de forma predeterminada, por lo que aparecerá en la lista del panel de Extensiones de ST (icono de cubos apilados) así:
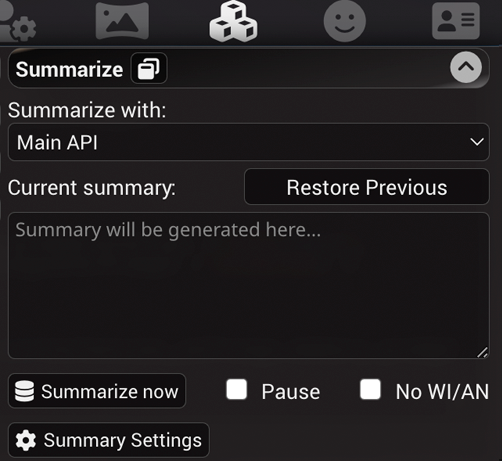
- Current summary - muestra y proporciona la capacidad de modificar el resumen actual. El resumen se actualiza e incorpora en los metadatos del archivo de chat para el mensaje que fue el último en contexto cuando se generó el resumen. Eliminar o editar un mensaje del chat que tiene un resumen adjunto revertirá el estado al último resumen válido.
- Restore Previous - elimina el resumen actual, revirtiendo al estado anterior. Esto es útil si el resumidor hace un trabajo deficiente en algún momento.
- Pause - marca esto para evitar que el resumen se actualice automáticamente. Esto es útil si deseas proporcionar tu propio resumen personalizado o para desactivar efectivamente el resumen borrando el cuadro y deteniendo las actualizaciones.
- Popup window - permite desprender el resumen en un panel de interfaz de usuario móvil en la barra lateral. Útil para el diseño de escritorio para tener fácil acceso a la configuración de resumición sin tener que navegar a través del menú de extensiones.
- Injection Template - define cómo se envolverá el resumen al insertarse en indicadores de chat regulares. Se debe usar una macro especial {{summary}} para denotar la ubicación exacta del estado del resumen actual en el texto de inyección del indicador.
- Injection Position - establece la ubicación de la inyección del indicador. Las opciones son las mismas que para Author's Notes: antes o después del indicador principal, o en el chat a una profundidad designada.
#
Fuentes de resumen admitidas
#
API Principal
La resumición estará impulsada por tu backend de IA actualmente seleccionado, modelo y configuraciones. Este método no requiere configuración adicional, solo una conexión API funcional.
Esta opción tiene los siguientes submodos que difieren según cómo se construye el indicador de resumen:
- Raw, blocking. El resumen se generará utilizando nada más que el indicador de resumición y el historial del chat. Los indicadores posteriores también incluirán el resumen anterior con mensajes que se enviaron después de la generación del resumen (ver ejemplo). Este modo puede (y lo hará) generar indicadores que tienen mucha variabilidad entre ellos, por lo que no se recomienda usarlo con backends que tienen tiempos de procesamiento de indicadores lentos, como llama.cpp y sus derivados.
- Raw, non-blocking. Igual que el anterior, pero la generación de chat no será bloqueada durante la generación del resumen. No todos los backends admiten solicitudes simultáneas, así que cambia al modo de bloqueo si la resumición falla.
- Classic, blocking. El indicador de resumición se enviará al final de tu indicador de generación habitual, como una instrucción del sistema neutral, sin omitir la tarjeta de personaje, el indicador principal, diálogos de ejemplo y otras partes de indicadores de chat. Esto generalmente resulta en indicadores que funcionan bien con la reutilización de indicadores procesados, por lo que se recomienda usarlo con llama.cpp y sus hermanos.
#
Configuración de resumen explicada
- Summary Prompt - define el indicador que se utilizará para crear un resumen. Puede incluir cualquiera de los macros conocidos, así como un macro especial {{words}} (ver abajo).
- Target summary length (words) - define el valor del macro {{words}} que se puede insertar en Summary Prompt. Esta configuración es completamente opcional y no tiene efecto alguno si el macro no se utiliza.
- API response length (tokens) - permite establecer una longitud de respuesta de API de anulación para generar resúmenes que difieren del valor establecido globalmente.
- Max messages per request (raw modes only) - configurado para limitar el número máximo de mensajes que se incluirán en una solicitud de resumición.
0significa sin limitación explícita, pero el número resultante de mensajes a resumir dependerá del tamaño máximo del contexto, calculado usando la fórmula:max summary buffer = context size - summarization prompt - previous summary - response length. Úsalo cuando desees obtener resúmenes más enfocados en modelos con tamaños de contexto grandes. - No WI/AN - omitir World Info y Author's Note del texto a resumir. Solo tiene efecto al usar el generador de indicadores clásico. El generador de indicadores Raw siempre omite WI/AN.
- Update every X messages - establece el intervalo en el cual se genera el resumen.
0significa que la resumición automática está deshabilitada, pero aún puedes activarla manualmente haciendo clic en el botón "Summarize now". Esto debe ajustarse según la rapidez con que el búfer de indicadores se llene completamente con mensajes de chat. Idealmente, querrías tener el primer resumen generado cuando los mensajes comienzan a descartarse del indicador. - Update every X words - lo mismo que arriba, pero usando palabras (¡no tokens!) en su lugar, teóricamente puede ser una medición más precisa debido a lo impredecible del contenido de los mensajes de chat, pero tu experiencia puede variar.
Si ambos controles deslizantes "Update every" se establecen en un valor distinto de cero, entonces ambos activarán actualizaciones de resumen en sus respectivos intervalos, dependiendo de qué suceda primero. Se recomienda encarecidamente actualizar estos valores en consecuencia cuando cambies a otro modelo que tenga tamaños de contexto diferentes; de lo contrario, la generación del resumen puede activarse demasiado a menudo o nunca.
Si no estás seguro de la configuración del intervalo, puedes hacer clic en el botón "varita mágica" encima de los controles deslizantes "Update every" para intentar adivinar los valores óptimos basados en algunas heurísticas simples. Una breve descripción del algoritmo es la siguiente:
- Calcular recuentos de tokens y palabras para todos los mensajes de chat
- Determinar la longitud del resumen objetivo en función de las palabras del indicador deseadas
- Calcular el número máximo de mensajes que caben en el indicador basado en la longitud promedio del mensaje
- Si "Max messages" está establecido, ajusta el promedio para tener en cuenta los mensajes que no se ajustan al límite del resumen
- Redondea hacia abajo los mensajes promedio ajustados por indicador a un múltiplo de 5
#
Indicadores de ejemplo
Raw prompt
System:
[Summarization prompt]
Previous summary.
User:
Message foo.
Char:
Message bar.Classic prompt
[Main prompt]
[Character card]
[Example dialogues]
User:
Message foo.
Char:
Message bar.
System:
[Summarization prompt]
#
Extras API
Servidor Extras con el módulo summarize podría ejecutar un modelo de resumición auxiliar (BART).
Tiene un tamaño de contexto muy pequeño (~1024 tokens), por lo que su capacidad para manejar resúmenes grandes es bastante limitada.
Para configurar la fuente de resumen de Extras, haz lo siguiente:
- Instala o Actualiza Extras a la última versión.
- Ejecuta Extras con el módulo
summarizehabilitado:python server.py --enable-modules=summarize
#
Cambiar modelo de resumen
Por defecto, Summarize utiliza el modelo Qiliang/bart-large-cnn-samsum-ChatGPT_v3 para propósitos de resumición.
Esto se puede cambiar utilizando el argumento de línea de comandos --summarization-model=(###Hugging-Face-Model-URL-Here###)
Un modelo Summarize alternativo conocido es Qiliang/bart-large-cnn-samsum-ElectrifAi_v10.