#
KoboldCpp
KoboldCpp es una API independiente para modelos GGML y GGUF.
Esta Calculadora VRAM de Nyx te dirá aproximadamente cuánta RAM/VRAM requiere tu modelo.
#
Inicio Rápido GPU Nvidia
Esta guía asume que estás usando Windows.
- Descarga la versión más reciente: https://github.com/LostRuins/koboldcpp/releases
- Inicia KoboldCpp. Puedes ver un pop-up de Microsoft Defender, haz clic en
Run Anyway. - A partir de la versión 1.58, KoboldCpp debería verse así:
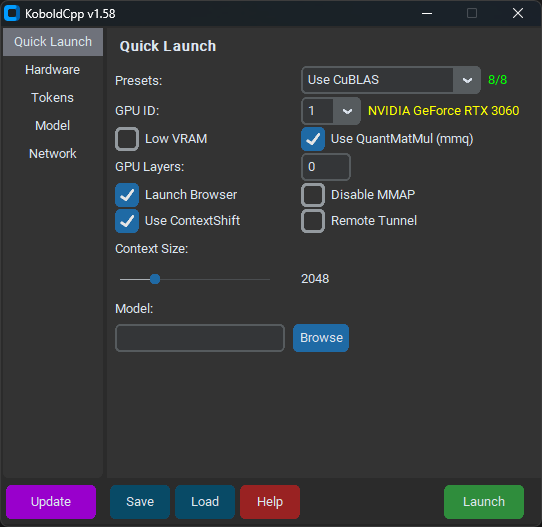
- En la pestaña
Quick Launch, selecciona el modelo y tuContext Sizepreferido. - Selecciona
Use CuBLASy asegúrate de que el texto amarillo junto aGPU IDcoincida con tu GPU. - No marques
Low VRAM, incluso si tienes VRAM baja. - A menos que tengas una GPU Nvidia 10-series o más antigua, desmarca
Use QuantMatMul (mmq). GPU Layersdebería haberse rellenado cuando cargaste tu modelo. Déjalo así por ahora.- En la pestaña
Hardware, marcaHigh Priority. - Haz clic en
Savepara no tener que configurar KoboldCpp en cada inicio. - Haz clic en
Launchy espera a que el modelo se cargue.
Deberías ver algo como esto:
Load Model OK: True
Embedded Kobold Lite loaded.
Starting Kobold API on port 5001 at http://localhost:5001/api/
Starting OpenAI Compatible API on port 5001 at http://localhost:5001/v1/
======
Please connect to custom endpoint at http://localhost:5001Ahora puedes conectarte a KoboldCpp dentro de SillyTavern con http://localhost:5001 como la URL de la API y comenzar a chatear.
¡Felicitaciones! ¡Ya terminaste!
Más o menos.
#
Capas GPU
KoboldCpp está funcionando, pero puedes mejorar el rendimiento asegurando que tantas capas como sea posible se descarguen en la GPU. Deberías ver algo como esto en la terminal:
llm_load_tensors: offloading 9 repeating layers to GPU
llm_load_tensors: offloaded 9/33 layers to GPU
llm_load_tensors: CPU buffer size = 25215.88 MiB
llm_load_tensors: CUDA0 buffer size = 7043.34 MiB
....................................................................................................
llama_kv_cache_init: CUDA_Host KV buffer size = 1479.19 MiB
llama_kv_cache_init: CUDA0 KV buffer size = 578.81 MiBNo tengas miedo de los números; esta parte es más fácil de lo que parece. CPU buffer size se refiere a cuánta RAM del sistema se está utilizando. Ignora eso. CUDA0 buffer size se refiere a cuánta VRAM de GPU se está utilizando. CUDA_Host KV buffer size y CUDA0 KV buffer size se refieren a cuánta VRAM de GPU se está dedicando al contexto de tu modelo. En este caso, KoboldCpp está usando aproximadamente 9 GB de VRAM.
Tengo 12 GB de VRAM, y solo 2 GB de VRAM se están utilizando para contexto, así que tengo aproximadamente 10 GB de VRAM restantes para cargar el modelo. Como 9 capas usaron aproximadamente 7 GB de VRAM y 7000 / 9 = 777.77 podemos asumir que cada capa usa aproximadamente 777.77 MIB de VRAM. 10,000 MIB / 777.77 = 12.8, así que redonderé hacia abajo y cargaré 12 capas con este modelo de ahora en adelante.
Ahora haz tu propio cálculo usando el modelo, el tamaño del contexto y la VRAM de tu sistema, e reinicia KoboldCpp:
- Si eres inteligente, hiciste clic en
Saveantes, y ahora puedes cargar tu configuración anterior conLoad. De lo contrario, selecciona la misma configuración que elegiste antes. - Cambia
GPU Layersa tu nuevo número optimizado para VRAM (12 capas en mi caso). - Haz clic en
Savepara guardar tu configuración actualizada.
Ahora deberías ver algo como esto:
llm_load_tensors: offloading 12 repeating layers to GPU
llm_load_tensors: offloaded 12/33 layers to GPU
llm_load_tensors: CPU buffer size = 25215.88 MiB
llm_load_tensors: CUDA0 buffer size = 9391.12 MiB
....................................................................................................
llama_kv_cache_init: CUDA_Host KV buffer size = 1286.25 MiB
llama_kv_cache_init: CUDA0 KV buffer size = 771.75 MiBKoboldCpp está usando aproximadamente 11.5 GB de mis 12 GB de VRAM. Esto debería funcionar mucho mejor que la configuración generada automáticamente por KoboldCpp.
¡Felicitaciones! ¡(De verdad) ya terminaste!
Para una mirada más profunda a la configuración de KoboldCpp, consulta la Guía de Configuración Simple Llama + SillyTavern Setup Guide de Kalomaze.